Computational Cognition & Representation Lab
Recovering the latent structures of mind and behavior
Our vision
We build computational models that recover the mental representations and knowledge structures driving how people perceive, attend to, and make sense of the world — probing these hidden structures through eye movements, language, and the patterns of what people recognize, confuse, and overlook.
Theme 1: Recovering the Priority Functions Behind Goal-Directed Gaze

When searching for a microwave, you attend to stoves and sinks — objects that signal where a microwave is likely to be
How do our goals shape where we look? When searching for an object in a cluttered scene, the brain must integrate target knowledge, scene context, and memory of where it has already looked into a moment-by-moment decision about where to fixate next. We use inverse reinforcement learning and transformer-based models to recover the latent reward functions and attentional policies underlying this process—treating the sequence of eye movements as a sparse but rich behavioral signal from which internal priority structures can be inferred. Trained on large-scale gaze datasets, our models reveal target-specific contextual priors, inhibitory tagging of visited locations, adaptive stopping rules, and the flexible integration of visual and linguistic signals.
Related Publications
Ahn, S., Yang, Z., Mondal, S., Xue, R., Hoai, M., Samaras, D., & Zelinsky, G. (under review). Reward modeling of goal-directed gaze control. PsyArXiv. doi: 10.31234/osf.io/zt5hm_v1
Mondal, S., Ahn, S., Yang, Z., Balasubramanian, N., Samaras, D., Zelinsky, G., & Hoai, M. (2024). Look hear: Gaze prediction for speech-directed human attention. In European Conference on Computer Vision (ECCV), 236–255.
Mondal, S., Yang, Z., Ahn, S., Samaras, D., Zelinsky, G., & Hoai, M. (2023). Gazeformer: Scalable, effective and fast prediction of goal-directed human attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1441–1450.
Chen, Y., Yang, Z., Ahn, S., Samaras, D., Hoai, M., & Zelinsky, G. (2021). COCO-Search18 fixation dataset for predicting goal-directed attention control. Scientific Reports, 11(1), 8776.
Yang, Z., Huang, L., Chen, Y., Wei, Z., Ahn, S., Zelinsky, G., Samaras, D., & Hoai, M. (2020). Predicting goal-directed human attention using inverse reinforcement learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 193–202.
Theme 2: Generative Object Representations and Robust Visual Inference
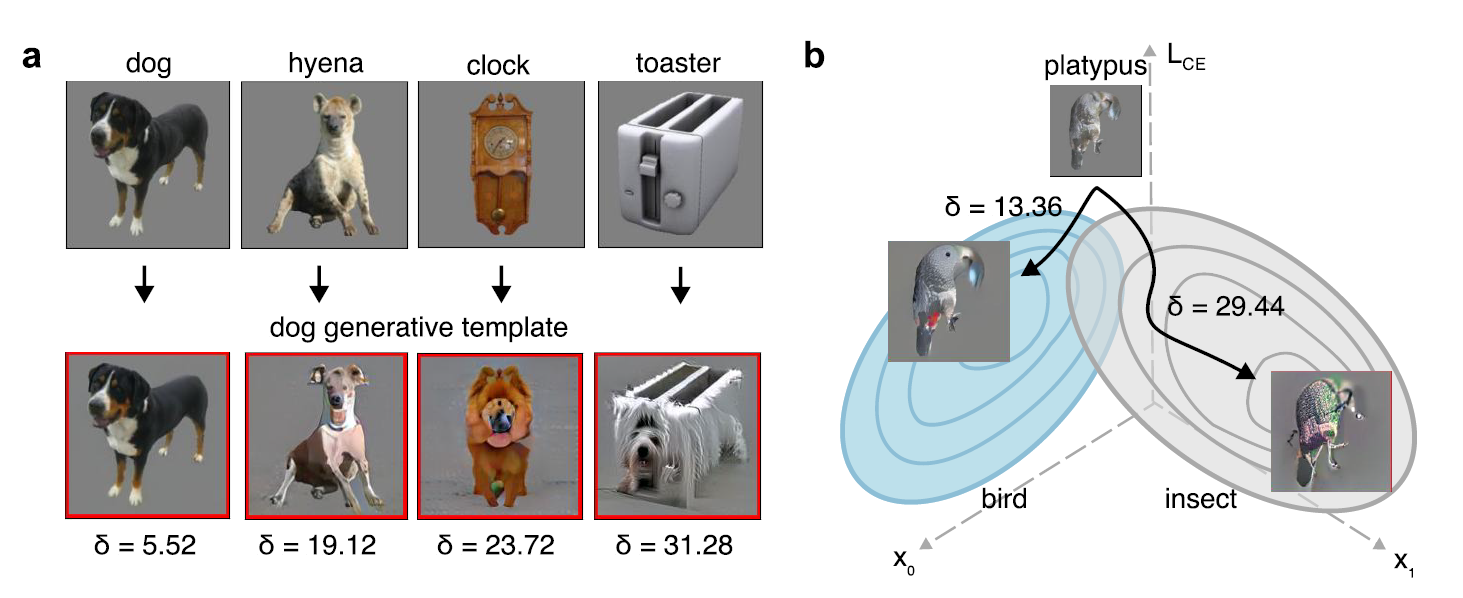
When searching for an object, you hold a target template in mind. We show this template may not be fixed prototype but is generated flexibly based on the visual input and the cost of this generation determines search efficiency. e.g., platypus is easily transformed into a bird but not into an insect (b, right).
Humans recognize objects under remarkably degraded conditions -- through noise, occlusion, blur, and unusual viewpoints. One explanation for this robustness is the brain's ability to generate internal representations of what it expects to see, then use these representations to guide perception top-down. Our work builds and tests computational models of this process: encoder-decoder networks that reconstruct object hypotheses ("generative target templates") from incomplete input, and attentional feedback that routes relevant features based on the best-matching reconstruction. We test these models against human behavior on matched tasks—comparing not only recognition accuracy but also the errors, illusions, and confusions that reflect the constructive nature of perception. More recently, we extend this approach to scene understanding using diffusion models, asking how the visual system infers coherent scenes from blurred peripheral input anchored by high-resolution foveated samples—generating image metamers indistinguishable from the original input.
Related Publications
Raina, R., Leite, A., Graikos, A., Ahn, S., Samaras, D., & Zelinsky, G. J. (2026). Generating metamers of human scene understanding. In International Conference on Learning Representations (ICLR).
Ahn, S., Adeli, H., & Zelinsky, G. (under review). Guiding attention during search using generative target template matching. PsyArXiv. doi: 10.31234/osf.io/9bgdv_v1
Ahn, S., Adeli, H., & Zelinsky, G. (2024). The attentive reconstruction of objects facilitates robust object recognition. PLOS Computational Biology, 20(6), e1012159.
Adeli, H., Ahn, S., & Zelinsky, G. J. (2023). A brain-inspired object-based attention network for multiobject recognition and visual reasoning. Journal of Vision, 23(5), 1–17.
Ahn, S., Adeli, H., & Zelinsky, G. (2022). Reconstruction-guided attention improves the robustness and shape processing of neural networks. Advances in Neural Information Processing Systems Workshops (NeurIPS Workshops), 1–13.
Theme 3: Reading Minds Through Eye Movement
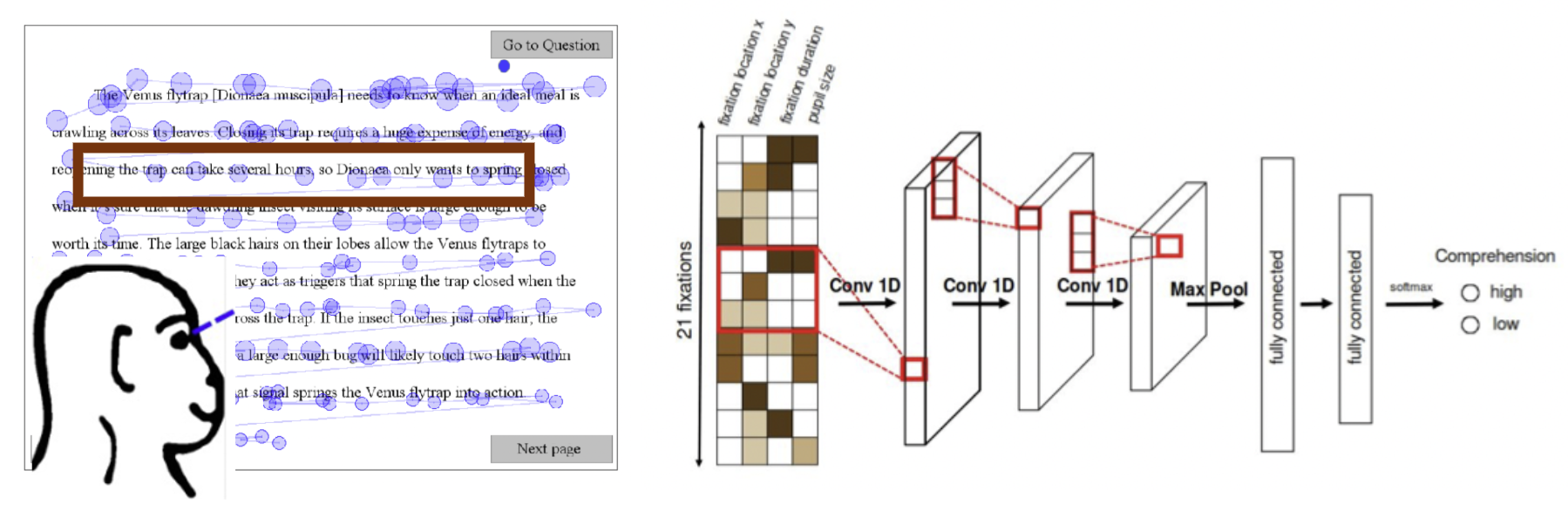
With just 21 fixations (about 5 seconds of eye movement data), we can predict whether you understood the text you read!
The way someone moves their eyes while reading a passage or scanning a document carries latent information about what they are understanding, what they find important, and how they are processing information. We develop computational methods to decode these hidden cognitive states from gaze behavior—predicting reading comprehension from fixation sequences, distinguishing reading from skimming in real time, and modeling user engagement while browsing webpages and mobile interfaces. These studies show that we can learn a surprisingly rich picture of someone's complex mental processes from something as simple as where and when they look.
Related Publications
Prasse, P., Reich, D. R., Makowski, S., Ahn, S., Scheffer, T., & Jäger, L. A. (2023). SP-EyeGAN: Generating synthetic eye movement data with Generative Adversarial Networks. In Proceedings of the Symposium on Eye Tracking Research and Applications (ETRA), 1–9.
Chakraborty, S., Wei, Z., Kelton, C., Ahn, S., Balasubramanian, A., Zelinsky, G., & Samaras, D. (2023). Predicting visual attention in graphic design documents. IEEE Transactions on Multimedia, 25, 4478–4493.
Ahn, S., Kelton, C., Balasubramanian, A., & Zelinsky, G. (2020). Towards predicting reading comprehension from gaze behavior. In Proceedings of the ACM Symposium on Eye Tracking Research & Applications (ETRA), 32, 1–5.
Kelton, C., Wei, Z., Ahn, S., Balasubramanian, A., Das, S., Samaras, D., & Zelinsky, G. (2019). Reading detection in real-time. In Proceedings of the ACM Symposium on Eye Tracking Research & Applications (ETRA), 1–5.
Moving forward…
So far, our work has focused on recovering the internal representations of an average person. Yet no two people see the world the same way—representations differ across individuals, cultures, and lived experiences. Going forward, the lab hopes to understand and model these differences: whose representations, whose priorities, and how they converge or diverge across people, groups, and contexts. Stay tuned!